一、概述 从网络下载视频数据,再进行本地 AI 分析,接着调用 LLM(ChatGPT、DeepSeek、Gemini、Qwen等) API,最后生成文档。Ray
方案
并发性
资源效率
备注
独立 placement group 每组绑定同一节点 ❌
⭐⭐
安全、可控但排队严重(strategy=”PACK”)
Actor 保持节点定位 + 并发执行 ✅
⭐⭐⭐
状态管理方便,适合流式任务或推理类任务
共享节点资源调度 + 同节点约束资源标签 ✅
⭐⭐⭐⭐
灵活调度,但实现稍复杂
二、需求 1、同一任务的步骤串行 四个步骤是串联的,后一个步骤会依赖于前一个步骤的结果。可以分别对四个步骤调用 ray.get,或者使用Task 依赖Task 依赖以便在 Dashboard 中能够跟踪执行状态。
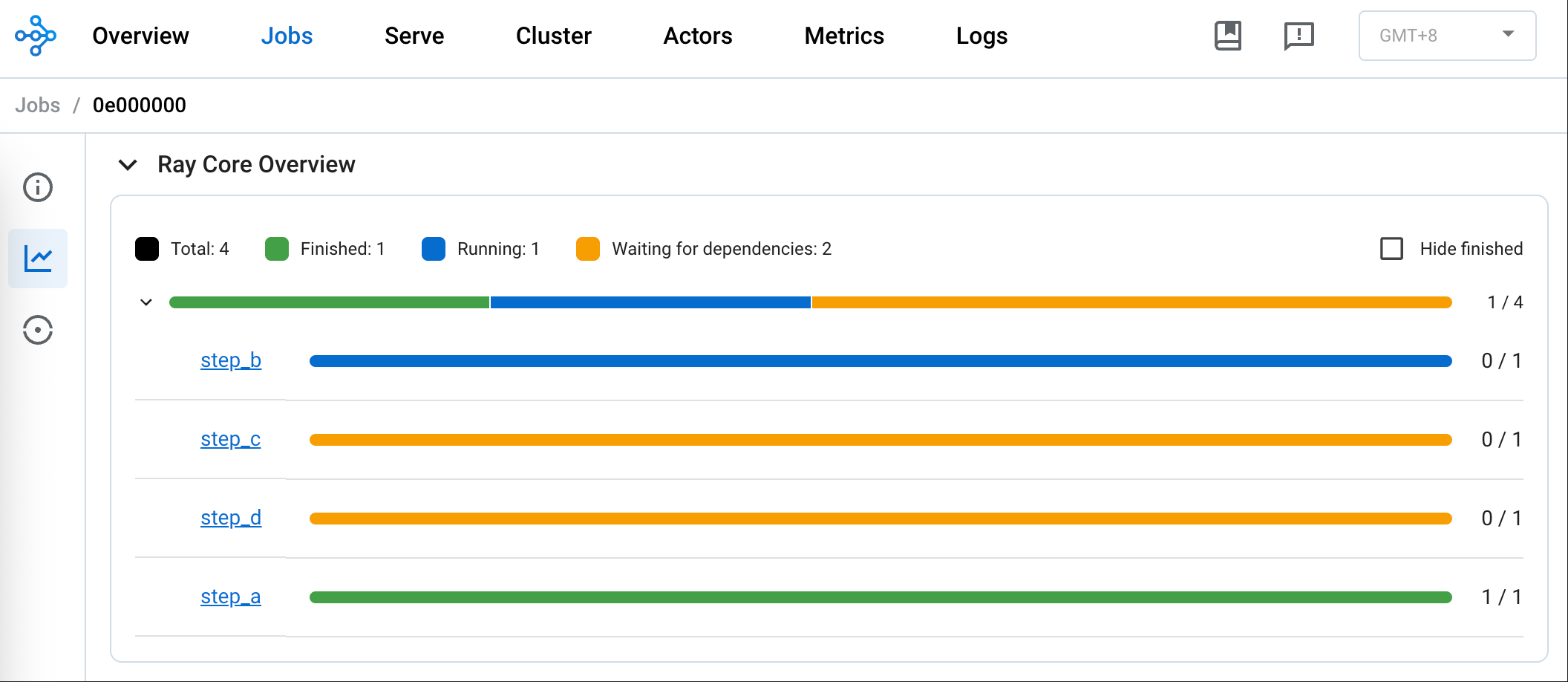
比如下图是在单节点下,同一任务的 step_a、step_b、step_c 和 step_d 串行。step_a 已经完成,step_b 正在运行,step_c 等待依赖的 step_b 完成,step_d 等待依赖的 step_c 完成。
通过日志也可以看出来同一任务的四个步骤串行。另外,执行不同步骤的 Node ID 是相同、Worker 的进程 ID 不尽相同。
1 2 3 4 (step_a pid=82717) [2025-08-07 00:23:03] [task_0] `step_a` Running on node 38ad38 127.0.0.1, GPUs: [] (step_b pid=82718) [2025-08-07 00:23:13] [task_0] `step_b` Running on node 38ad38 127.0.0.1, GPUs: [0] (step_c pid=82717) [2025-08-07 00:23:43] [task_0] `step_c` Running on node 38ad38 127.0.0.1, GPUs: [] (step_d pid=82717) [2025-08-07 00:23:49] [task_0] `step_d` Running on node 38ad38 127.0.0.1, GPUs: []
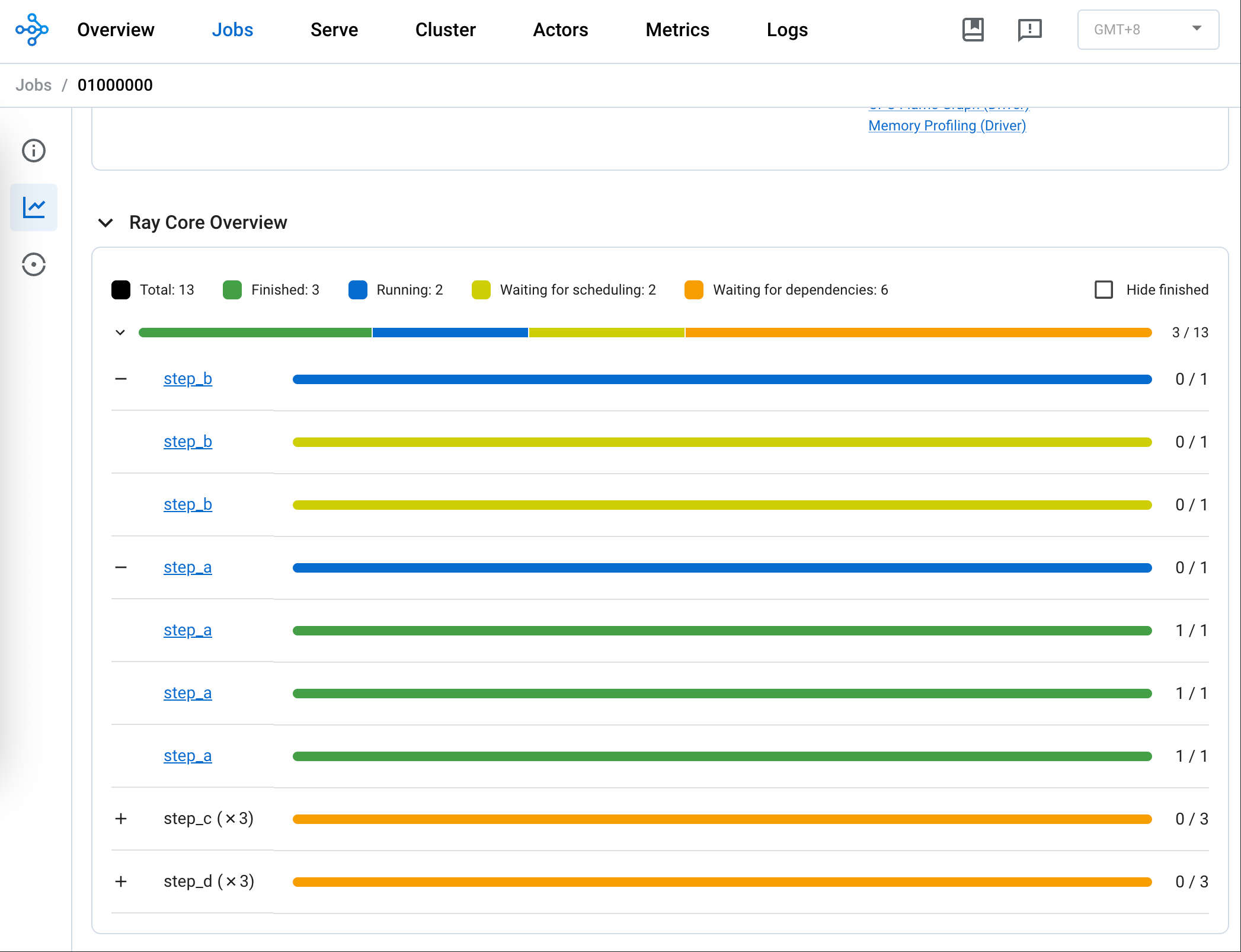
2、单节点:不同任务的步骤并行 下图是单节点单 GPU 下,step_a 和 step_b 在同一任务的步骤串行,不同任务的步骤并行。
遗憾的是上图无法分辨不同任务,不过可以看出 step_a 和 step_b 都处于 Running 状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 (step_a pid=70715) [2025-08-07 00:11:23] [task_0] `step_a` Running on node 38ad38 127.0.0.1, GPUs: [] (step_a pid=70715) [2025-08-07 00:11:34] [task_1] `step_a` Running on node 38ad38 127.0.0.1, GPUs: [] (step_b pid=70904) [2025-08-07 00:11:34] [task_0] `step_b` Running on node 38ad38 127.0.0.1, GPUs: [0] (step_a pid=70715) [2025-08-07 00:11:44] [task_2] `step_a` Running on node 38ad38 127.0.0.1, GPUs: [] (step_a pid=70715) [2025-08-07 00:11:54] [task_3] `step_a` Running on node 38ad38 127.0.0.1, GPUs: [] (step_c pid=70715) [2025-08-07 00:12:04] [task_0] `step_c` Running on node 38ad38 127.0.0.1, GPUs: [] (step_b pid=71343) [2025-08-07 00:12:04] [task_1] `step_b` Running on node 38ad38 127.0.0.1, GPUs: [0] (step_d pid=70715) [2025-08-07 00:12:10] [task_0] `step_d` Running on node 38ad38 127.0.0.1, GPUs: [] (step_c pid=70715) [2025-08-07 00:12:34] [task_1] `step_c` Running on node 38ad38 127.0.0.1, GPUs: [] (step_b pid=71511) [2025-08-07 00:12:34] [task_2] `step_b` Running on node 38ad38 127.0.0.1, GPUs: [0] (step_d pid=70715) [2025-08-07 00:12:40] [task_1] `step_d` Running on node 38ad38 127.0.0.1, GPUs: [] (step_c pid=70715) [2025-08-07 00:13:04] [task_2] `step_c` Running on node 38ad38 127.0.0.1, GPUs: [] (step_b pid=72571) [2025-08-07 00:13:05] [task_3] `step_b` Running on node 38ad38 127.0.0.1, GPUs: [0] (step_d pid=70715) [2025-08-07 00:13:10] [task_2] `step_d` Running on node 38ad38 127.0.0.1, GPUs: [] (step_c pid=70715) [2025-08-07 00:13:35] [task_3] `step_c` Running on node 38ad38 127.0.0.1, GPUs: [] (step_d pid=70715) [2025-08-07 00:13:41] [task_3] `step_d` Running on node 38ad38 127.0.0.1, GPUs: []
3、多节点:避免跨节点数据传输 由于视频数据量相对较大,在进行本地 AI 分析的时候要避免数据在节点之间传输。下载和本地 AI 分析功能做在同一个 Step 里,但这样做会使得不同任务的步骤无法并行。比如任务 A 已经下载完毕并且已经在进行本地 AI 分析,任务 B 本可以马上下载但必须等任务 A的本地 AI 分析完成。所以继续保持下载和本地 AI 分析功能分开,通过某种方式使得任务中下载步骤由哪台服务器完成就在这台服务器上进行该任务的本地 AI 分析操作。key 形如 “node:IP” 的 resource。让下载步骤里返回服务器的 IP,再让本地 AI 分析需要这个 resource,从而调度到拥有指定 IP 的服务器(也就是下载步骤执行的服务器)上。
4、多节点:是否避免节点饥饿? 在多节点的情况下,某个节点下载完成后正在进行本地 AI 分析,可能导致接下来的任务也分配下载步骤到本节点,从而导致没有在下载且有空闲 GPU 资源的其他节点产生饥饿。如果要处理这种情况,只能牺牲不同任务下载和本地 AI 分析的并行, 也就是说不是那么”着急”地一有任务就马上进行下载。
将下载和本地 AI 分析两个步骤合并到一个步骤。如上所述,这样会导致不同任务的下载和本地 AI 分析无法并行。
使用 Actor。
使用 Placement Group。
使用 Ray resources 进行限制。
我倾向于方法 4,因为只需要改动非常少的代码即可实现。
方法4类似于 NodeAffinitySchedulingStrategy 将 soft 设置为 false 。
三、Talk is cheap 1、启动 Ray 1 2 ray start --head --port=6380 --num-cpus=16 --num-gpus=1 --resources='{"head": 8, "step_a_slot": 1000}' --block
head :当前节点为 Head 节点。节点有一张 GPU。port :使用 6480 而不是 6479 是为了避免与其他 Redis 服务冲突。resources :自定义资源。重点。
head 后面会讲到,会希望 step_d 只在Head 节点运行。step_a_slot 目的是 Ray 在群集运行时限制多个任务的下载步骤的并发,下载比本地 AI 分析快的情况下,可能导致某些服务器下载过多,其他有空闲 GPU 资源的服务器由于没有数据可用而无事可做;如果耗时情况相反则可加大该值。单机也可以适当设置大一些,或者代码 step_a 使用 step_a_slot 少一点。
特别注意,step_a_slot 只是一定程度上缓解而不是解决 GPU 饥饿问题。
1 2 3 ray stop ray start --address='192.168.10.117:6380' --num-cpus=16 --num-gpus=1 --resources='{"step_a_slot": 1000}' --block
address :Head 节点的 IP 地址。
2、任务代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import osos.environ["RAY_DEDUP_LOGS" ] = "0" import timefrom datetime import datetimefrom concurrent.futures import ThreadPoolExecutor, as_completedray.init() def simulate_work (task_id, task_name, duration ): start_str = datetime.now().strftime('%Y-%m-%d %H:%M:%S' ) node_id = ray.get_runtime_context().get_node_id() node_ip_address = ray.util.get_node_ip_address() print ( f"[{start_str} ] [{task_id} ] `{task_name} ` Running on node {node_id[:6 ]} {node_ip_address} , GPUs: {ray.get_gpu_ids()} " ) time.sleep(duration) @ray.remote(resources={ "step_a_slot" : 1000 } )def step_a (task_id ): simulate_work(task_id, "step_a" , 10 ) node_ip_address = ray.util.get_node_ip_address() return node_ip_address @ray.remote(num_gpus=1 ) def step_b (task_id, step_a_result ): simulate_work(task_id, "step_b" , 30 ) return f"[{task_id} ] step_b success" def create_step_b (task_id, step_a_result ): resource_key = f"node:{step_a_result} " future_b = step_b.options(resources={ resource_key: 0.01 }).remote(task_id, step_a_result) return future_b @ray.remote def step_c (task_id, step_b_result ): simulate_work(task_id, "step_c" , 6 ) return f"[{task_id} ] step_c success" @ray.remote(resources={ "head" : 1 } )def step_d (task_id, step_c_result ): simulate_work(task_id, "step_d" , 1 ) return f"[{task_id} ] step_d success" def schedule_task (task_id ): node_ip_address = ray.get(step_a.remote(task_id)) future_b = create_step_b(task_id, node_ip_address) future_c = step_c.remote(task_id, future_b) future_d = step_d.remote(task_id, future_c) return future_d def get_current_node_resources (): node_id = ray.get_runtime_context().get_node_id() for node in ray.nodes(): if node["NodeID" ] == node_id: return node["Resources" ] return None if __name__ == "__main__" : with ThreadPoolExecutor(max_workers=4 ) as executor: futures = [executor.submit(schedule_task, f"task_{i} " ) for i in range (4 )] futures = [future.result() for future in as_completed(futures)] results = ray.get(futures) print ("All tasks done:" ) for r in results: print (r)
首先,schedule_task 方法中调用了 ray.get 以获取 step_a 的返回值的节点的 IP 地址。当然,这样在 Dashboard 中,如果 step_a 没执行完成是看不到后续的 step_b、 step_c 和 step_d 的。key 形如 node:127.0.0.1 的资源,可以通过上面代码中的 get_current_node_resources 方法获取验证。
1 2 3 4 5 6 7 8 9 10 { "object_store_memory" : 2147483648 , "node:127.0.0.1" : 1 , "head" : 8 , "step_a_slot" : 1000 , "CPU" : 16 , "node:__internal_head__" : 1 , "memory" : 9066250240 , "GPU" : 2 }
所以可以在 create_step_b 这个非 Task 方法设置运行 step_b 所需要的资源,即 resource_key。注意 resource_key 要设置小一点,否则在多 GPU 的情况下可能会导致无法并行运行 step_b。step_a 和 step_b 运行在同一个节点上的目的。
由于断开了 step_a 和 step_b 的代码层面上的直接依赖,也就是 step_b 的参数没有依赖 step_a 的结果,在 create_step_b 之前,Dashboard 上是看不到 step_b、step_c、step_d 在等待被调度(Waiting for scheduling)的。
参考资料 Ray 官方文档 Ray: Tasks Ray: Actors Ray: Placement Group Ray: NodeAffinitySchedulingStrategy Ray: 给 Task 传递对象引用